依存ツリーなしでシードデータ:Faker の代わりに小さな PHP CLI を書いた
依存ツリーなしでシードデータ:Faker の代わりに小さな PHP CLI を書いた
新しい Postgres スキーマにユーザー 50 件と投稿 200 件を入れて、ダッシュボードのデモが空に見えないようにしたかった。Laravel のシーダーは Laravel の外では動かない。Faker はどこでも動くが依存ツリーが付いてくる。PHP の
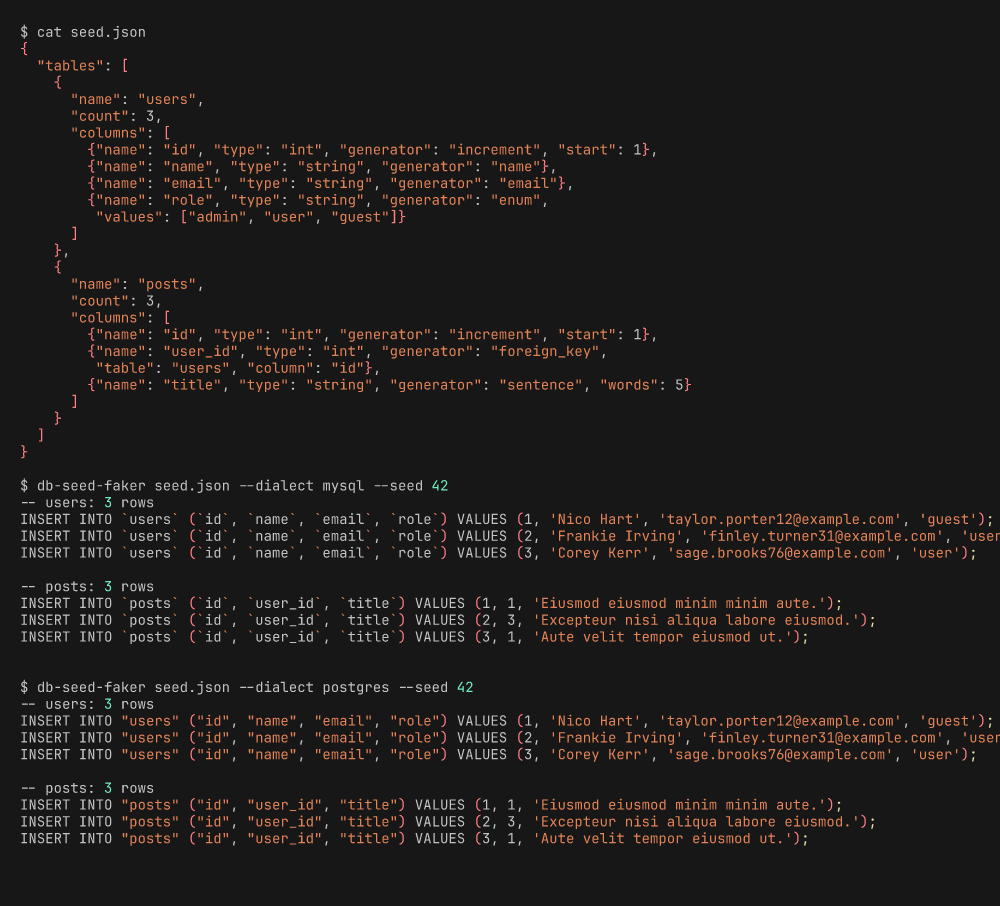
json_decodeはもう入っている。そこで JSON 設定を読んでINSERT文を吐く最小のものを書いた ── 外部キー、決定論的シード、方言対応エスケープ付きで約 600 行。
📦 GitHub: https://github.com/sen-ltd/db-seed-faker
フレームワーク依存のシードデータ問題
どの Web フレームワークもシードデータについて意見を持っている。Laravel には Seeder + Factory、Rails にはフィクスチャと factory_bot、Django には dumpdata / loaddata、Spring には data.sql。エコシステム内ではうまく動くが、外に出た瞬間 ── 「サイドプロジェクトの新しい Postgres スキーマに psql -f seed.sql してスクショが撮れる状態にしたい」── に無力になる。
Faker ライブラリは半分を解決するが大きい。fakerphp/faker はインストール時 1.2 MB で、ほとんどが不要なロケールデータ。さらに Composer 依存=サイドプロジェクトに composer install とロックファイル。デモ用としては大げさすぎる。
欲しかったのは docker run --rm -v $(pwd):/work db-seed-faker /work/seed.json > seed.sql で完結するもの。インストール不要、フレームワーク不要。--seed 42 で決定論的出力。
設定ファイルの形
ユーザー 50 件と投稿 200 件を生成する設定:
{
"tables": [
{
"name": "users",
"count": 50,
"columns": [
{"name": "id", "type": "int", "generator": "increment", "start": 1},
{"name": "name", "type": "string", "generator": "name"},
{"name": "email", "type": "string", "generator": "email"},
{"name": "role", "type": "string", "generator": "enum",
"values": ["admin", "user", "guest"]},
{"name": "age", "type": "int", "generator": "number", "min": 18, "max": 99}
]
},
{
"name": "posts",
"count": 200,
"columns": [
{"name": "id", "type": "int", "generator": "increment", "start": 1},
{"name": "user_id", "type": "int", "generator": "foreign_key",
"table": "users", "column": "id"},
{"name": "title", "type": "string", "generator": "sentence", "words": 5},
{"name": "body", "type": "text", "generator": "paragraph", "sentences": 3}
]
}
]
}
2 つの設計判断:
JSON(YAML ではない)。 PHP 8 の標準ライブラリに YAML パーサーはない。json_decode は組み込み。
テーブル順序 = ロード順序。 posts は users の後に来て、外部キーは先に宣言されたテーブルを参照する。トポロジカルソートは意図的に入れていない。ソースファイルを上から下に読めば依存順がわかるべきだし、循環外部キーを表現できないのは機能だ。
ジェネレータインターフェース
interface GeneratorInterface
{
public function generate(int $rowIndex, array $context, Rng $rng): string|int|null;
}
3 つのパラメータ:現テーブル内の行インデックス、前テーブルの生成済み行データ(テーブル名をキーとする)、シード済み RNG。戻り値は string|int|null に絞った ── bool は整数で、float はシードデータでは使わない。
組み込みジェネレータは 10 種:increment、number、name、email、sentence、paragraph、datetime、uuid、foreign_key、enum。レジストリは match 式 1 つ。新しいジェネレータの追加 = ここに 1 行+ src/Generators/ にファイル 1 つ。
外部キージェネレータ
全ジェネレータの中で最も面白い挙動を持つのがこれ。エミッタがテーブルを順に処理するとき、生成済みの各行を $context[$tableName][$rowIndex] に保存する。ForeignKeyGenerator::generate() は後のテーブルの処理中に呼ばれ、ターゲットテーブルから一様ランダムに行を選んで要求カラムの値を返す:
public function generate(int $rowIndex, array $context, Rng $rng): string|int|null
{
$rows = $context[$this->table];
$pick = $rng->intRange(0, count($rows) - 1);
return $rows[$pick][$this->column];
}
このインメモリキャッシュのため、ツールはストリーミングしない。シードデータ生成にはそれで問題ない。10 万行の親テーブル × integer id でも数 MB。
FK ジェネレータが意図的にやらないこと:クランピング。すべての親行が均等な確率で選ばれるので、200 投稿 / 50 ユーザーなら平均約 4 投稿/ユーザーで自然なばらつきが出る。
エスケープ:方言が食い違う唯一の場所
// シングルクォートを二重にする。MySQL の \' は NO_BACKSLASH_ESCAPES で壊れる
return "'" . str_replace("'", "''", $value) . "'";
'' 形式は SQL 標準で、MySQL の任意の sql_mode、Postgres、SQLite すべてで動く。識別子クォートは MySQL がバッククォート、Postgres/SQLite が標準のダブルクォート。
決定性:シード済み RNG
すべてのジェネレータは単一の Rng インスタンスを通してランダム性を流す:
final class Rng
{
private int $state;
public function __construct(int $seed) { /* ... */ }
// Park-Miller minimal LCG
public function next(): int
{
$this->state = ($this->state * 48271) % 0x7fffffff;
return $this->state;
}
}
Park-Miller は 50 年の歴史があり、暗号用途には不向き。シードデータには完璧。--seed 42 で今日も明日も 6 ヶ月後の新しいコンテナイメージでもビット単位で同一の SQL が出る。
mt_rand を使わなかった理由:PHP のポイントリリース間で出力が変わった歴史があること、mt_srand がグローバルに触るので PHPUnit の同一プロセス内でテストが互いのシードを上書きすること。インスタンススコープの Park-Miller なら両方回避できる。
トレードオフ
- ロケール非対応。 名前は英語の姓名各 50 件の CC0 リストから。日本語名が必要なら
data/*.txtを差し替える。 - FK 数の関係制約なし。 「各ユーザーに 2-10 投稿」は表現できない。均一分布のみ。
- ストリーミングなし。 FK 解決のため行コンテキストをメモリに保持。100 万行なら
generate_seriesを直接使う。 - スキーマ生成なし。
CREATE TABLEはマイグレーションツールの仕事。 - 一意性制約非対応。 email ジェネレータに 2 桁のサフィックスがあるが、1000 ユーザーで衝突しうる。
- Faker 互換レイヤーなし。 検討したが、コードが倍になるので見送り。
30 秒で試す
git clone https://github.com/sen-ltd/db-seed-faker
cd db-seed-faker
docker build -t db-seed-faker .
cat > seed.json << 'EOT'
{
"tables": [{
"name": "users",
"count": 5,
"columns": [
{"name": "id", "type": "int", "generator": "increment", "start": 1},
{"name": "name", "type": "string", "generator": "name"},
{"name": "email", "type": "string", "generator": "email"}
]
}]
}
EOT
docker run --rm -v $(pwd):/work db-seed-faker /work/seed.json \
--dialect postgres --seed 42
5 件の INSERT INTO "users" が stdout に出力される。同じシード、同じ出力、毎回。
書いて得たもの
設定スペクトラムの「JSON ファイル + 10 ジェネレータのレジストリ」にスイートスポットがある。 新規コントリビュータが午後 1 回で全体を読めるサイズで、実際のデモニーズを実際にカバーする大きさ。ロケール、プロバイダ、クランピング、スキーマ生成 ── 追加の軸を検討するたびに「本当に必要か?」と確認し、答えはたいてい No だった。
決定性は安く、価値がある。 Park-Miller 12 行、シードフラグ 1 本で、シードデータが git でクリーンに diff できる。
約 600 行、ランタイム依存ゼロ、Docker イメージ 51 MB、PHPUnit テスト 49 件。MIT ライセンス。
SEN 合同会社の 100 超のポートフォリオシリーズ エントリ #181。