p99 で嘘をつかない HTTP 負荷テストツールを Rust で書いた
p99 で嘘をつかない HTTP 負荷テストツールを Rust で書いた
http-bench: 指定した時間またはリクエスト数だけ HTTP リクエストを打ち込み、RPS・レイテンシパーセンタイル・エラー内訳を報告する小さな Rust CLI。約 900 行、依存 5 つ、コンテナイメージ 11.6 MB。
HTTP 負荷テストツールはすでにいくつも優秀なものがある ── wrk、hey、oha、vegeta、bombardier。それでも自分で作った。その理由が(たぶん)面白いのと、一つは完全に好みの問題だ。
📦 GitHub: https://github.com/sen-ltd/http-bench
既存ツールで埋まらなかったギャップ
負荷テストの「正解」は今でも wrk だと思っている。速いし、LuaJIT スクリプトフックは強力だし、デファクトを名乗る資格がある。問題は C で書かれていて、クリーンな環境に入れるのが思ったより面倒なこと。新品の Alpine コンテナ、再インストール直後の macOS、SSH で入った他人の Debian マシン ── どれでも 10 秒以内に docker run で使えるテストツールが欲しい。
hey は「簡単にインストールできる」問題を美しく解決している ── Go のバイナリをどこにでも置くだけ。ただしデフォルトで p99 レイテンシを出力せず、平均と最大値だけ。ユーザー向けのサービスにおいて、平均は嘘で最大値は外れ値の一点でしかない。ロングテールの中間が欲しいのだ。
oha は実はかなり近い。Rust 製、HDR ヒストグラム使用、インストール可能、出力もリッチ。しかしフルスクリーン TUI で、tmux からベンチを回して出力を grep したいときに TUI は要らない。プレーンテキストか JSON ブロブが stdout に出てほしい。
結局、欲しかったのはこういうものだった:
- コンテナに 1 行で入れられるバイナリ
- 平均ではなく正しいパーセンタイルを出す
- テキストか JSON を stdout に出力するだけ。TUI は不要
- 一度で読み切れるサイズで、必要なら自分で改造できる
それが http-bench。依存は 5 つ(clap、tokio、reqwest+rustls、hdrhistogram、humantime)、ソース約 900 行、マルチステージ Alpine イメージ 11.6 MB。
HDR ヒストグラムが省略不可な理由
最初に話したいのは、このツールを「素朴」から「実際に正しい」に引き上げた一つの決定 ── レイテンシに Vec<Duration> ではなく HDR ヒストグラムを使うこと。
素朴なパーセンタイルの計算方法はこうだ。全サンプルをベクタに記録し、最後にソートして samples[samples.len() * 0.99] を p99 とする。小規模なら問題ないが、負荷テスト規模では 2 つの問題がある:
- メモリがリクエスト数に比例して増える。 50,000 RPS × 60 秒 = 300 万個の
Duration。破滅的ではないが、タダでもない。 - 最後のソートもタダではない。 パーセンタイル計算に
O(n log n)かかり、複数パーセンタイルやライブ表示が欲しい場合には辛い。
HDR(High Dynamic Range)ヒストグラムは、わずかな精度と引き換えに定数時間の記録とクエリを実現する。値を対数バケットに入れるため、10 億サンプルでも 100 サンプルでもほぼ同じメモリ使用量で、任意のパーセンタイルを O(バケット数) ── 実質一瞬 ── で返せる。
「わずかな精度」は設定可能。http-bench では有効数字 3 桁に設定しており、パーセンタイルクエリが返す値はそのバケットに入った実サンプルの 0.1% 以内に収まる。不安定なネットワーク越しの HTTP レイテンシ計測には十分すぎる精度だ。
ラッパーはこんな感じ:
pub struct LatencyHistogram {
h: Histogram<u64>,
}
impl LatencyHistogram {
pub fn new() -> Self {
// 1 µs .. 60 s, 3 significant figures.
let h = Histogram::<u64>::new_with_bounds(1, 60_000_000, 3)
.expect("bounds/sigfig are valid constants");
Self { h }
}
pub fn record(&mut self, d: Duration) {
let us = d.as_micros().min(u64::MAX as u128) as u64;
let us = us.clamp(1, 60_000_000);
let _ = self.h.record(us);
}
pub fn quantile(&self, q: f64) -> Duration {
if self.h.is_empty() {
return Duration::ZERO;
}
Duration::from_micros(self.h.value_at_quantile(q))
}
pub fn merge(&mut self, other: &LatencyHistogram) {
self.h.add(&other.h)
.expect("merging two histograms with identical bounds cannot fail");
}
}
merge メソッドが重要なのは、ワーカープールの構造に関係する。各ワーカーはプライベートなヒストグラムを持ち、ロックなしで記録する。実行終了後に merge でグローバルヒストグラムに畳み込む。ホットループでの競合ゼロ、最後に正しい集約。
ワーカーはスレッドではなくタスク
2 つ目の設計判断。「並行数」はここでは tokio タスクを意味し、OS スレッドではない。--concurrency 1000 を渡すと、マルチスレッドランタイムを共有する 1000 個の tokio タスクが起動する。tokio タスクはヒープ数 KB、OS スレッドはスタック約 1 MB+スケジューラスロット。タスク方式なら、スレッド方式では倒れるような並行数まで無理なくスケールする。
各タスクのホットループは基本的にこう:
loop {
if stop.load(Ordering::Relaxed) {
break;
}
let prev = remaining.fetch_sub(1, Ordering::Relaxed);
if prev == 0 {
remaining.fetch_add(1, Ordering::Relaxed);
break;
}
let outcome = fire(&client, &cfg).await;
state.record(outcome);
}
停止条件は 2 つ。時間モードでは AtomicBool がスリーパータスクによってデッドライン到達時に true に反転。リクエスト数モードでは AtomicU64 がカウントダウンし、ゼロに最初に到達したワーカーが勝つ。オーバーシュート後の fetch_add(1) は小さな誠実さ ── カウンターは要求数ではなく実際に発射された数を報告する。
Coordinated Omission 問題(正直に言う)
ここからは正直に書かなければならない部分。この問題を解決したふりをするのが、負荷テストツールが嘘をつくメカニズムだからだ。
Coordinated Omission とは、負荷テストツールが「遅いレスポンスを待っている間のストール」をレイテンシ分布から隠してしまう障害モードのこと。典型的なシナリオ:1 秒 1000 リクエストを送ろうとしている。サーバーが 500 ms ヒックアップする。その間ワーカーはインフライトリクエストを待ち続け、新しいリクエストをゼロ本しか送らない。p99 には 500 ms のリクエストが 1 本だけ現れ、「ユーザーの 99% は 2 ms 以下で、1 人だけ不運で 0.5 秒」と結論づける。実際には数百の「送られるはずだった」リクエストがまったく送信されておらず、本当のユーザーがその間にアクセスすれば 500 ms を食らっていたはずだ。
Gil Tene(HDRHistogram の作者でもある)がこの問題について詳しく書いている。厳密な修正は、「ワーカーごとに最大速度」ではなく意図したレートに対してリクエストをスケジューリングし、レスポンスが遅延したとき、ストール中に生成されたであろう仮想サンプルをヒストグラムに遡及的に追加すること。
http-bench はこれをやっていない。 wrk がデフォルトで実行するのと同じ、素朴な open-loop-at-max-concurrency パターンを実行する。README でもこの記事でも正直にそう書いている。Coordinated Omission を無視しながらきれいな p99 を印刷するツールは、積極的にミスリードしている。
実務的に言えば、このツールは「このエンドポイントはだいたいどれくらい速くて、飽和時のレイテンシ分布はどんな形か」という問いには使える。「特定の目標 RPS でサーバーが 500 ms ヒックアップしたとき、ユーザーは実際に何を体験するか」という問いには使えない。それには wrk2 のようなクローズドループツールか、適切なロードシェイプ対応のジェネレータが必要。
セーフティゲート
3 つ目の意図的な設計判断。デフォルトで http-bench は、明らかに自分のものでないターゲットへのリクエストを拒否する。プライベート IP レンジ、*.local、*.localhost、リテラルの localhost は許可。それ以外は --allow-internet が必要。
fn ipv4_is_private(v4: Ipv4Addr) -> bool {
let [a, b, _, _] = v4.octets();
v4.is_loopback()
|| v4.is_unspecified()
|| v4.is_link_local()
|| a == 10
|| (a == 172 && (16..=31).contains(&b))
|| (a == 192 && b == 168)
}
毎秒数千リクエストを許可なく他人のサーバーに叩き込むのは、「迷惑」から「クラウドプロバイダの利用規約違反」、場合によっては「不正アクセス禁止法上のサービス拒否攻撃」までありうる。拒否をデフォルトにし、オプトインをフラグ 1 本にするのは、エルゴノミクス的にほぼコストゼロで、将来の自分の URL タイプミスから守ってくれる。
30 秒で試す
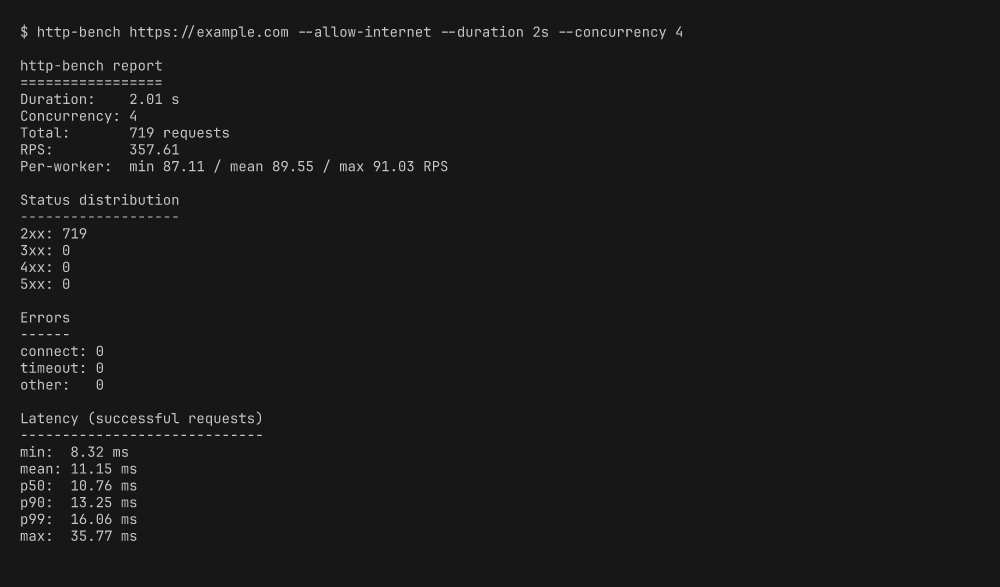
git clone https://github.com/sen-ltd/http-bench.git
cd http-bench
docker build -t http-bench .
# デフォルトではパブリックターゲットを拒否
docker run --rm http-bench https://example.com
# exit 2、--allow-internet を案内するメッセージ
# 明示的なオプトインで短時間実行
docker run --rm http-bench https://example.com \
--allow-internet --duration 2s --concurrency 4 --timeout 3s
トレードオフ
- Coordinated Omission 補正なし。 上述の通り。気になるなら
wrk2を使う。 - HTTP/2 多重化なし。
reqwestは HTTP/2 対応だが、各ワーカーは一度に 1 本の論理接続を持つ。 - ストリーミングボディなし。
--body/--body-fileはメモリに全読みしてVec<u8>をリクエストごとにクローン。JSON ペイロードなら問題なし、GB 級のアップロードには不向き。 - Lua スクリプティングなし。
wrkのキラー機能。ここにはなく、予定もない。
このツールが何であるか:小さくて読みやすく、限界について正直な負荷テストツール。docker run でどのマシンでも動き、HDR ヒストグラムで正確なパーセンタイルを出し、セーフティゲートで他人のサーバーを誤って落とさない。tmux ペインで回しておきたいのはまさにこういうもの。
SEN 合同会社の 100 超のポートフォリオシリーズ エントリ #172。