Prisma スキーマを手書きパーサで解析して Mermaid ER 図を生成する CLI
課題
Prisma は TypeScript エコシステムのデファクト ORM だが、公式の ER 図ジェネレータがない。有名なコミュニティプラグイン prisma-erd-generator は Puppeteer を起動して PNG をレンダリングする。動くが、テキスト変換であるべき処理にしては大仰だし CI では辛い(apt-get install chromium、Docker レイヤキャッシュ、etc.)。そして出力がラスター画像なので diff が取れないし grep もできないし README に貼れない。
GitHub、GitLab、dev.to、Obsidian、Notion — いずれも Mermaid をネイティブにレンダリングする。schema.prisma を読んで Mermaid テキストを出力する CLI があればそれで足りる。書いてみたら、「パーサを書く練習」としても良い題材だった。
📦 GitHub: https://github.com/sen-ltd/prisma-erd
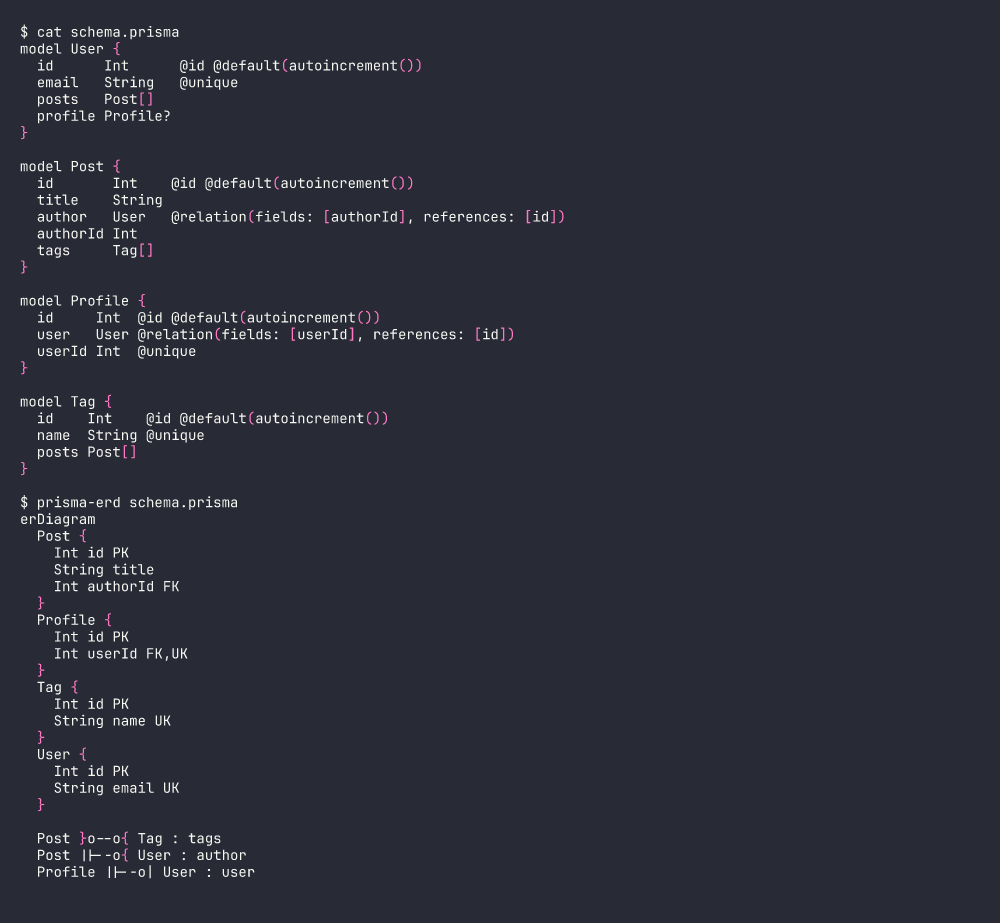
Prisma のスキーマがパースしやすい理由
- ブロック構造 —
model X { ... }、enum X { ... }等。最外殻はブロックのループ - 式の評価が不要 —
@default(autoincrement())の中身を評価する必要はなく、@relationにfields:があるかだけ見ればいい - 空白が程よくヒント — フィールドは改行区切り。属性引数は複数行に跨げるが、手書きトークナイザで自然に扱える
- 識別子セットが小さい — キーワードは
model、enum、datasource、generator程度。演算子文法もパターンマッチ構文もない
再帰降下 — 最もシンプルなパース戦略 — でそのまま動く。
ステップ 1: 小さなレキサ
ソーステキストを { kind, value, line, col } のトークン列に変換する。コアループ:
while (i < n) {
const ch = source[i]!;
if (ch === '/' && source[i + 1] === '/') {
while (i < n && source[i] !== '\n') i++;
continue;
}
if (ch === '\n') { push('newline', '\n', line, col); i++; line++; col = 1; continue; }
if (ch === '@') {
if (source[i + 1] === '@') { push('double_at', '@@', line, col); i += 2; col += 2; }
else { push('at', '@', line, col); i++; col++; }
continue;
}
if (ch === '"') { /* 閉じクォートまで読む */ }
if (isIdentStart(ch)) { /* 識別子継続文字まで読む */ }
// ...
}
改行をトークンとして残すのがポイント。フィールド宣言 email String @unique は改行で終端される。空白を全部潰すとフィールドの境界が分からなくなる。
@ と @@ を別トークン種にする。@id はフィールド属性、@@id([a, b]) はモデルレベルの複合主キー。レキサで区別しておけばパーサで先読みが不要。
約 150 行。正規表現エンジンなし、バックトラックなし。
ステップ 2: 再帰降下でブロックをパース
export function parse(source: string): Schema {
const cursor = new Cursor(tokenize(source));
const models: Model[] = [];
const enums: EnumDecl[] = [];
while (cursor.peek().kind !== 'eof') {
cursor.eatNewlines();
const t = cursor.peek();
if (t.kind === 'eof') break;
switch (t.value) {
case 'model': models.push(parseModel(cursor)); break;
case 'enum': enums.push(parseEnum(cursor)); break;
case 'datasource':
case 'generator':
case 'type':
case 'view': skipNamedBlock(cursor); break;
default: throw new ParseError(`unknown top-level keyword "${t.value}"`, t.line, t.col);
}
}
return { models, enums };
}
トップレベル文法がそのままコードになっている。datasource と generator は ER 図に不要なので skipNamedBlock でスキップ。
属性引数のパースではフルの式パースではなく 括弧バランスキャプチャ を使う:
function captureBalanced(cursor: Cursor): string {
const open = cursor.expect('lparen');
let depth = 1;
const parts: string[] = [];
while (depth > 0) {
const t = cursor.next();
if (t.kind === 'eof') throw new ParseError('unterminated attribute args', open.line, open.col);
if (t.kind === 'lparen') { depth++; parts.push('('); continue; }
if (t.kind === 'rparen') { depth--; if (depth === 0) break; parts.push(')'); continue; }
if (t.kind === 'string') { parts.push(JSON.stringify(t.value)); continue; }
parts.push(t.value);
}
return parts.join(' ').replace(/\s+/g, ' ').trim();
}
@relation(fields: [authorId], references: [id]) が文字列 fields : [ authorId ] , references : [ id ] になる。後段のアナライザは fields: があるかを正規表現でマッチするだけ。エレガントではないが、図の生成には @id、@relation、@unique の 3 属性しか必要ないので、完全な AST を作るよりはるかにシンプル。
ステップ 3: リレーションのペアリング
Prisma はリレーションを両側に書く:
model User {
posts Post[]
}
model Post {
author User @relation(fields: [authorId], references: [id])
authorId Int
}
図にエッジは 1 本だけ欲しい。全モデルフィールドを走査して RawRelation[] を集め、ペアリングする:
for (let i = 0; i < raw.length; i++) {
if (used.has(i)) continue;
const a = raw[i]!;
let matched = -1;
for (let j = i + 1; j < raw.length; j++) {
if (used.has(j)) continue;
const b = raw[j]!;
if (b.field.type !== a.modelName) continue;
if (a.field.type !== b.modelName) continue;
if (a.relationName !== b.relationName) continue;
matched = j;
break;
}
used.add(i);
if (matched >= 0) { used.add(matched); pairs.push({ a, b: raw[matched]! }); }
else { pairs.push({ a }); }
}
FK を持つ側(fields: がある方)をエッジの from にする。リストフィールドは “many”、オプショナルスカラーは “zero-or-one”、必須スカラーは “one”。両方がリストなら暗黙の多対多(Prisma の不可視ジョインテーブル)。
Mermaid 出力
const CARDINALITY_LEFT = { 'one': '||', 'zero-or-one': '|o', 'many': '}o' };
const CARDINALITY_RIGHT = { 'one': '||', 'zero-or-one': 'o|', 'many': 'o{' };
function formatEdge(edge: RelationEdge): string {
const left = CARDINALITY_LEFT[edge.fromCardinality];
const right = CARDINALITY_RIGHT[edge.toCardinality];
return ` ${edge.from} ${left}--${right} ${edge.to} : ${edge.label}`;
}
Mermaid の crow’s-foot 記法は対称的: || が「ちょうど 1」、o| が「0 or 1」、o{ が「0 or 多」。左右でグリフが鏡像になるので 2 テーブルが必要。1 回デバッグセッションを経て左右を入れ替えなくなった。
Mermaid のフィールド型カラムに ? や [] が使えないので、修飾子を除去して null 可能性は NULL マーカーで表現する。
テスト
45 の vitest テスト:
- レキサ (8): トークン種別、
@vs@@、文字列エスケープ、コメント - パーサ (6): モデル抽出、型修飾子、リレーション属性キャプチャ、parse エラー
- アナライザ (11): 1:1/1:N/M:N 検出、エッジ重複排除、PK/FK 検出、フィルタ
- フォーマッタ (8): crow’s-foot 表記、型サニタイズ、DOT/JSON 出力
- メイン (12): 引数パース、exit コード、
--includeフィルタ
全ステージが純粋関数なので全テストが 300ms 以内に完了する。
意図的な制限
- 属性式の評価はしない —
@default(now())は不透明な文字列として扱う - マルチファイルスキーマ未対応 — Prisma のプレビュー機能。単一ファイルのみ
- 参照アクション非表示 —
onDelete: Cascadeは JSON 出力にはあるが Mermaid には入れていない - エラー回復が甘い — 最初のエラーで停止。リンタではないので許容範囲
試してみる
git clone https://github.com/sen-ltd/prisma-erd
cd prisma-erd
docker build -t prisma-erd .
docker run --rm -v "$PWD/tests/fixtures:/work" prisma-erd /work/blog.prisma
出力された Mermaid テキストを README の ```mermaid フェンスに貼れば GitHub がそのまま描画する。
# モデルをフィルタ:
docker run --rm -v "$PWD/tests/fixtures:/work" prisma-erd /work/blog.prisma --include User,Post
# JSON 出力:
docker run --rm -v "$PWD/tests/fixtures:/work" prisma-erd /work/blog.prisma --format json
# Graphviz DOT:
docker run --rm -v "$PWD/tests/fixtures:/work" prisma-erd /work/blog.prisma --format dot | dot -Tpng > erd.png
136 MB のランタイムイメージ、ランタイム依存ゼロ、パーサ約 300 行、プロジェクト全体で 1000 行以下。
SEN 合同会社 の 100 超ポートフォリオシリーズ #168。